Testa DITT Företag på Minuter
Skapa ditt konto och lansera din AI-chatbot på några minuter. Helt anpassningsbar, ingen kodning krävs - börja engagera dina kunder direkt!
Klar på några minuter
Ingen kodning krävs
De ödmjuka början: Tidiga regelbaserade system
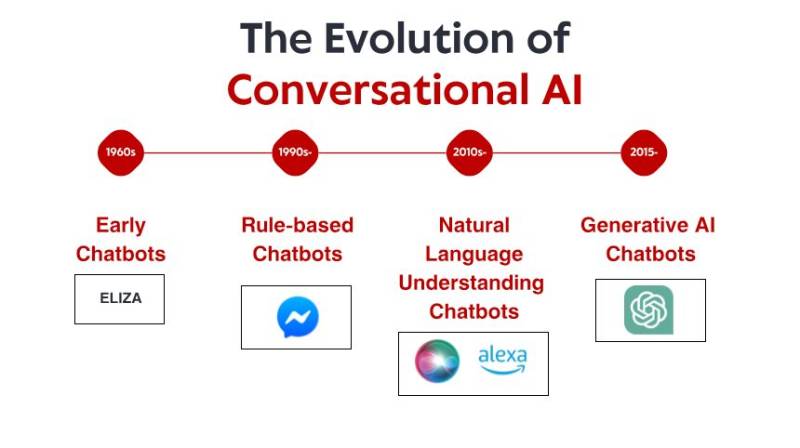
Historien om konversationsbaserad AI börjar på 1960-talet, långt innan smartphones och röstassistenter blev vanliga hushållsartiklar. I ett litet laboratorium på MIT skapade datavetaren Joseph Weizenbaum vad många anser vara den första chatboten: ELIZA. ELIZA, som var utformad för att simulera en Rogeriansk psykoterapeut, arbetade sig igenom enkla mönstermatchnings- och substitutionsregler. När en användare skrev "Jag känner mig ledsen" kunde ELIZA svara med "Varför känner du dig ledsen?" – vilket skapade en illusion av förståelse genom att omformulera påståenden till frågor.
Det som gjorde ELIZA anmärkningsvärt var inte dess tekniska sofistikering – med dagens mått mätt var programmet otroligt grundläggande. Snarare var det den djupgående effekten det hade på användarna. Trots att de visste att de pratade med ett datorprogram utan någon egentlig förståelse, skapade många människor känslomässiga band med ELIZA och delade djupt personliga tankar och känslor. Detta fenomen, som Weizenbaum själv tyckte var oroande, avslöjade något grundläggande om mänsklig psykologi och vår vilja att antropomorfisera även de enklaste konversationsgränssnitten.
Under 1970- och 1980-talen följde regelbaserade chattrobotar ELIZAs mall med stegvisa förbättringar. Program som PARRY (som simulerar en paranoid schizofren) och RACTER (som "författade" en bok med titeln "The Policeman's Beard is Half Constructed") höll sig stadigt inom det regelbaserade paradigmet – med hjälp av fördefinierade mönster, sökordsmatchning och mallbaserade svar.
Dessa tidiga system hade allvarliga begränsningar. De kunde inte förstå språk, lära sig av interaktioner eller anpassa sig till oväntade input. Deras kunskap var begränsad till de regler som deras programmerare uttryckligen hade definierat. När användare oundvikligen avvek från dessa gränser splittrades illusionen av intelligens snabbt och avslöjade den mekaniska naturen under. Trots dessa begränsningar lade dessa banbrytande system grunden som all framtida konversations-AI skulle bygga på.
Det som gjorde ELIZA anmärkningsvärt var inte dess tekniska sofistikering – med dagens mått mätt var programmet otroligt grundläggande. Snarare var det den djupgående effekten det hade på användarna. Trots att de visste att de pratade med ett datorprogram utan någon egentlig förståelse, skapade många människor känslomässiga band med ELIZA och delade djupt personliga tankar och känslor. Detta fenomen, som Weizenbaum själv tyckte var oroande, avslöjade något grundläggande om mänsklig psykologi och vår vilja att antropomorfisera även de enklaste konversationsgränssnitten.
Under 1970- och 1980-talen följde regelbaserade chattrobotar ELIZAs mall med stegvisa förbättringar. Program som PARRY (som simulerar en paranoid schizofren) och RACTER (som "författade" en bok med titeln "The Policeman's Beard is Half Constructed") höll sig stadigt inom det regelbaserade paradigmet – med hjälp av fördefinierade mönster, sökordsmatchning och mallbaserade svar.
Dessa tidiga system hade allvarliga begränsningar. De kunde inte förstå språk, lära sig av interaktioner eller anpassa sig till oväntade input. Deras kunskap var begränsad till de regler som deras programmerare uttryckligen hade definierat. När användare oundvikligen avvek från dessa gränser splittrades illusionen av intelligens snabbt och avslöjade den mekaniska naturen under. Trots dessa begränsningar lade dessa banbrytande system grunden som all framtida konversations-AI skulle bygga på.
Kunskapsrevolutionen: Expertsystem och strukturerad information
Under 1980-talet och början av 1990-talet uppstod expertsystem – AI-program utformade för att lösa komplexa problem genom att härma mänskliga experters beslutsfattande förmåga inom specifika områden. Även om de inte primärt var utformade för konversation, representerade dessa system ett viktigt evolutionärt steg för konversationsbaserad AI genom att introducera mer sofistikerad kunskapsrepresentation. Expertsystem som MYCIN (som diagnostiserade bakterieinfektioner) och DENDRAL (som identifierade kemiska föreningar) organiserade information i strukturerade kunskapsbaser och använde inferensmotorer för att dra slutsatser. När den tillämpades på konversationsgränssnitt tillät denna metod chatbotar att gå bortom enkel mönstermatchning och mot något som liknade resonemang – åtminstone inom smala områden. Företag började implementera praktiska tillämpningar som automatiserade kundtjänstsystem med hjälp av denna teknik. Dessa system använde vanligtvis beslutsträd och menybaserade interaktioner snarare än friformskonversationer, men de representerade tidiga försök att automatisera interaktioner som tidigare krävde mänsklig intervention. Begränsningarna förblev betydande. Dessa system var sköra och kunde inte hantera oväntade inmatningar på ett elegant sätt. De krävde enorma ansträngningar från kunskapsingenjörer för att manuellt koda information och regler. Och kanske viktigast av allt, de kunde fortfarande inte riktigt förstå naturligt språk i dess fulla komplexitet och tvetydighet.
Ändå etablerade denna era viktiga koncept som senare skulle bli avgörande för modern konversationsbaserad AI: strukturerad kunskapsrepresentation, logisk inferens och domänspecialisering. Scenen höll på att bana väg för ett paradigmskifte, även om tekniken inte riktigt var där än.
Ändå etablerade denna era viktiga koncept som senare skulle bli avgörande för modern konversationsbaserad AI: strukturerad kunskapsrepresentation, logisk inferens och domänspecialisering. Scenen höll på att bana väg för ett paradigmskifte, även om tekniken inte riktigt var där än.
Förståelse av naturligt språk: Genombrottet inom beräkningslingvistik
I slutet av 1990-talet och början av 2000-talet ökade fokuset på naturlig språkbehandling (NLP) och datorlingvistik. Istället för att försöka handkoda regler för varje möjlig interaktion började forskare utveckla statistiska metoder för att hjälpa datorer att förstå de inneboende mönstren i mänskligt språk.
Denna förändring möjliggjordes av flera faktorer: ökad beräkningskraft, bättre algoritmer och, framför allt, tillgången till stora textkorpusar som kunde analyseras för att identifiera språkliga mönster. System började införliva tekniker som:
Ordklassmärkning: Identifiera om ord fungerade som substantiv, verb, adjektiv etc.
Igenkänning av namngivna enheter: Upptäcka och klassificera egennamn (personer, organisationer, platser).
Sentimentanalys: Bestämning av den känslomässiga tonen i text.
Parsing: Analysera meningsstruktur för att identifiera grammatiska relationer mellan ord.
Ett anmärkningsvärt genombrott kom med IBMs Watson, som berömt besegrade mänskliga mästare i frågesportprogrammet Jeopardy! 2011. Även om det inte strikt sett var ett konversationssystem, visade Watson oöverträffade förmågor att förstå frågor om naturligt språk, söka igenom stora kunskapsdatabaser och formulera svar – förmågor som skulle visa sig avgörande för nästa generations chattrobotar. Kommersiella applikationer följde snart. Apples Siri lanserades 2011 och gav vanliga konsumenter konversationsgränssnitt. Även om Siri var begränsat av dagens standarder, representerade det ett betydande framsteg när det gällde att göra AI-assistenter tillgängliga för vanliga användare. Microsofts Cortana, Googles Assistant och Amazons Alexa följde, och alla drev framåt den senaste tekniken inom konsumentorienterad konversations-AI. Trots dessa framsteg kämpade system från denna era fortfarande med kontext, sunt förnuft och att generera verkligt naturliga svar. De var mer sofistikerade än sina regelbaserade förfäder men förblev fundamentalt begränsade i sin förståelse av språk och världen.
Denna förändring möjliggjordes av flera faktorer: ökad beräkningskraft, bättre algoritmer och, framför allt, tillgången till stora textkorpusar som kunde analyseras för att identifiera språkliga mönster. System började införliva tekniker som:
Ordklassmärkning: Identifiera om ord fungerade som substantiv, verb, adjektiv etc.
Igenkänning av namngivna enheter: Upptäcka och klassificera egennamn (personer, organisationer, platser).
Sentimentanalys: Bestämning av den känslomässiga tonen i text.
Parsing: Analysera meningsstruktur för att identifiera grammatiska relationer mellan ord.
Ett anmärkningsvärt genombrott kom med IBMs Watson, som berömt besegrade mänskliga mästare i frågesportprogrammet Jeopardy! 2011. Även om det inte strikt sett var ett konversationssystem, visade Watson oöverträffade förmågor att förstå frågor om naturligt språk, söka igenom stora kunskapsdatabaser och formulera svar – förmågor som skulle visa sig avgörande för nästa generations chattrobotar. Kommersiella applikationer följde snart. Apples Siri lanserades 2011 och gav vanliga konsumenter konversationsgränssnitt. Även om Siri var begränsat av dagens standarder, representerade det ett betydande framsteg när det gällde att göra AI-assistenter tillgängliga för vanliga användare. Microsofts Cortana, Googles Assistant och Amazons Alexa följde, och alla drev framåt den senaste tekniken inom konsumentorienterad konversations-AI. Trots dessa framsteg kämpade system från denna era fortfarande med kontext, sunt förnuft och att generera verkligt naturliga svar. De var mer sofistikerade än sina regelbaserade förfäder men förblev fundamentalt begränsade i sin förståelse av språk och världen.
Maskininlärning och den datadrivna metoden
Mitten av 2010-talet markerade ytterligare ett paradigmskifte inom konversationsbaserad AI med den allmänna användningen av maskininlärningstekniker. Istället för att förlita sig på handgjorda regler eller begränsade statistiska modeller började ingenjörer bygga system som kunde lära sig mönster direkt från data – och mycket av det.
Under denna era ökade intentionsklassificering och entitetsutvinning som kärnkomponenter i konversationsarkitekturen. När en användare gjorde en förfrågan skulle systemet:
Klassificera den övergripande avsikten (t.ex. boka ett flyg, kontrollera vädret, spela musik)
Extrahera relevanta entiteter (t.ex. platser, datum, låttitlar)
Koppla dessa till specifika handlingar eller svar
Facebooks (nu Metas) lansering av sin Messenger-plattform 2016 gjorde det möjligt för utvecklare att skapa chattrobotar som kunde nå miljontals användare, vilket utlöste en våg av kommersiellt intresse. Många företag skyndade sig att implementera chattrobotar, även om resultaten var blandade. Tidiga kommersiella implementeringar frustrerade ofta användare med begränsad förståelse och stela konversationsflöden.
Den tekniska arkitekturen för konversationssystem utvecklades också under denna period. Den typiska metoden involverade en pipeline av specialiserade komponenter:
Automatisk taligenkänning (för röstgränssnitt)
Förståelse av naturligt språk
Dialoghantering
Generering av naturligt språk
Text-till-tal (för röstgränssnitt)
Varje komponent kunde optimeras separat, vilket möjliggjorde stegvisa förbättringar. Dessa pipeline-arkitekturer led dock ibland av felspridning – misstag i tidiga skeden kaskaderade genom systemet.
Medan maskininlärning avsevärt förbättrade funktionerna, kämpade systemen fortfarande med att upprätthålla sammanhang under långa samtal, förstå implicit information och generera verkligt mångsidiga och naturliga svar. Nästa genombrott skulle kräva en mer radikal metod.
Under denna era ökade intentionsklassificering och entitetsutvinning som kärnkomponenter i konversationsarkitekturen. När en användare gjorde en förfrågan skulle systemet:
Klassificera den övergripande avsikten (t.ex. boka ett flyg, kontrollera vädret, spela musik)
Extrahera relevanta entiteter (t.ex. platser, datum, låttitlar)
Koppla dessa till specifika handlingar eller svar
Facebooks (nu Metas) lansering av sin Messenger-plattform 2016 gjorde det möjligt för utvecklare att skapa chattrobotar som kunde nå miljontals användare, vilket utlöste en våg av kommersiellt intresse. Många företag skyndade sig att implementera chattrobotar, även om resultaten var blandade. Tidiga kommersiella implementeringar frustrerade ofta användare med begränsad förståelse och stela konversationsflöden.
Den tekniska arkitekturen för konversationssystem utvecklades också under denna period. Den typiska metoden involverade en pipeline av specialiserade komponenter:
Automatisk taligenkänning (för röstgränssnitt)
Förståelse av naturligt språk
Dialoghantering
Generering av naturligt språk
Text-till-tal (för röstgränssnitt)
Varje komponent kunde optimeras separat, vilket möjliggjorde stegvisa förbättringar. Dessa pipeline-arkitekturer led dock ibland av felspridning – misstag i tidiga skeden kaskaderade genom systemet.
Medan maskininlärning avsevärt förbättrade funktionerna, kämpade systemen fortfarande med att upprätthålla sammanhang under långa samtal, förstå implicit information och generera verkligt mångsidiga och naturliga svar. Nästa genombrott skulle kräva en mer radikal metod.
Transformatorrevolutionen: Neurala språkmodeller
År 2017 markerade en vändpunkt i AI-historien med publiceringen av "Attention Is All You Need", som introducerade Transformer-arkitekturen som skulle revolutionera bearbetning av naturligt språk. Till skillnad från tidigare metoder som bearbetade text sekventiellt kunde Transformers betrakta en hel passage samtidigt, vilket gjorde det möjligt för dem att bättre fånga relationer mellan ord oavsett deras avstånd från varandra.
Denna innovation möjliggjorde utvecklingen av allt kraftfullare språkmodeller. År 2018 introducerade Google BERT (Bidirectional Encoder Representations from Transformers), vilket dramatiskt förbättrade prestandan för olika språkförståelseuppgifter. År 2019 släppte OpenAI GPT-2, vilket demonstrerade oöverträffade förmågor att generera sammanhängande, kontextuellt relevant text.
Det mest dramatiska språnget kom 2020 med GPT-3, som skalade upp till 175 miljarder parametrar (jämfört med GPT-2:s 1,5 miljarder). Denna massiva ökning i skala, i kombination med arkitektoniska förfiningar, producerade kvalitativt annorlunda funktioner. GPT-3 kunde generera anmärkningsvärt människolik text, förstå sammanhang över tusentals ord och till och med utföra uppgifter som den inte uttryckligen tränades på.
För konversationsbaserad AI översattes dessa framsteg till chatbotar som kunde:
Upprätthålla sammanhängande konversationer över många vändningar
Förstå nyanserade frågor utan uttrycklig träning
Generera olika, kontextuellt lämpliga svar
Anpassa deras ton och stil för att matcha användaren
Hantera tvetydigheter och förtydliga vid behov
Lanseringen av ChatGPT i slutet av 2022 förde dessa funktioner till mainstream och lockade över en miljon användare inom några dagar efter lanseringen. Plötsligt hade allmänheten tillgång till konversationsbaserad AI som verkade kvalitativt annorlunda än allt som kom tidigare – mer flexibelt, mer kunnigt och mer naturligt i sina interaktioner.
Kommersiella implementeringar följde snabbt, med företag som integrerade stora språkmodeller i sina kundtjänstplattformar, verktyg för innehållsskapande och produktivitetsapplikationer. Det snabba införandet återspeglade både det tekniska språnget och det intuitiva gränssnittet som dessa modeller tillhandahöll – konversation är trots allt det mest naturliga sättet för människor att kommunicera.
Denna innovation möjliggjorde utvecklingen av allt kraftfullare språkmodeller. År 2018 introducerade Google BERT (Bidirectional Encoder Representations from Transformers), vilket dramatiskt förbättrade prestandan för olika språkförståelseuppgifter. År 2019 släppte OpenAI GPT-2, vilket demonstrerade oöverträffade förmågor att generera sammanhängande, kontextuellt relevant text.
Det mest dramatiska språnget kom 2020 med GPT-3, som skalade upp till 175 miljarder parametrar (jämfört med GPT-2:s 1,5 miljarder). Denna massiva ökning i skala, i kombination med arkitektoniska förfiningar, producerade kvalitativt annorlunda funktioner. GPT-3 kunde generera anmärkningsvärt människolik text, förstå sammanhang över tusentals ord och till och med utföra uppgifter som den inte uttryckligen tränades på.
För konversationsbaserad AI översattes dessa framsteg till chatbotar som kunde:
Upprätthålla sammanhängande konversationer över många vändningar
Förstå nyanserade frågor utan uttrycklig träning
Generera olika, kontextuellt lämpliga svar
Anpassa deras ton och stil för att matcha användaren
Hantera tvetydigheter och förtydliga vid behov
Lanseringen av ChatGPT i slutet av 2022 förde dessa funktioner till mainstream och lockade över en miljon användare inom några dagar efter lanseringen. Plötsligt hade allmänheten tillgång till konversationsbaserad AI som verkade kvalitativt annorlunda än allt som kom tidigare – mer flexibelt, mer kunnigt och mer naturligt i sina interaktioner.
Kommersiella implementeringar följde snabbt, med företag som integrerade stora språkmodeller i sina kundtjänstplattformar, verktyg för innehållsskapande och produktivitetsapplikationer. Det snabba införandet återspeglade både det tekniska språnget och det intuitiva gränssnittet som dessa modeller tillhandahöll – konversation är trots allt det mest naturliga sättet för människor att kommunicera.
Testa DITT Företag på Minuter
Skapa ditt konto och lansera din AI-chatbot på några minuter. Helt anpassningsbar, ingen kodning krävs - börja engagera dina kunder direkt!
Klar på några minuter
Ingen kodning krävs
Multimodala funktioner: Utöver textbaserade konversationer
Medan text har dominerat utvecklingen av konversationsbaserad AI har man under de senaste åren sett en utveckling mot multimodala system som kan förstå och generera flera typer av media. Denna utveckling återspeglar en grundläggande sanning om mänsklig kommunikation – vi använder inte bara ord; vi gestikulerar, visar bilder, ritar diagram och använder vår omgivning för att förmedla mening.
Visuellspråksmodeller som DALL-E, Midjourney och Stable Diffusion visade förmågan att generera bilder från textbeskrivningar, medan modeller som GPT-4 med visuella funktioner kunde analysera bilder och diskutera dem intelligent. Detta öppnade nya möjligheter för konversationsgränssnitt:
Kundtjänstrobotar som kan analysera foton av skadade produkter
Shoppare som kan identifiera varor från bilder och hitta liknande produkter
Utbildningsverktyg som kan förklara diagram och visuella koncept
Tillgänglighetsfunktioner som kan beskriva bilder för synskadade användare
Röstfunktioner har också utvecklats dramatiskt. Tidiga talgränssnitt som IVR-system (Interactive Voice Response) var notoriskt frustrerande och begränsade till stela kommandon och menystrukturer. Moderna röstassistenter kan förstå naturliga talmönster, ta hänsyn till olika accenter och talstörningar och svara med alltmer naturligt klingande syntetiserade röster.
Sammanslagningen av dessa funktioner skapar verkligt multimodal konversations-AI som sömlöst kan växla mellan olika kommunikationslägen baserat på kontext och användarbehov. En användare kan börja med en textfråga om att reparera sin skrivare, skicka ett foto av felmeddelandet, få ett diagram som markerar relevanta knappar och sedan växla till röstinstruktioner medan deras händer är upptagna med reparationen.
Denna multimodala metod representerar inte bara ett tekniskt framsteg utan ett grundläggande skifte mot mer naturlig människa-datorinteraktion – att möta användare i vilket kommunikationsläge som helst som fungerar bäst för deras nuvarande kontext och behov.
Visuellspråksmodeller som DALL-E, Midjourney och Stable Diffusion visade förmågan att generera bilder från textbeskrivningar, medan modeller som GPT-4 med visuella funktioner kunde analysera bilder och diskutera dem intelligent. Detta öppnade nya möjligheter för konversationsgränssnitt:
Kundtjänstrobotar som kan analysera foton av skadade produkter
Shoppare som kan identifiera varor från bilder och hitta liknande produkter
Utbildningsverktyg som kan förklara diagram och visuella koncept
Tillgänglighetsfunktioner som kan beskriva bilder för synskadade användare
Röstfunktioner har också utvecklats dramatiskt. Tidiga talgränssnitt som IVR-system (Interactive Voice Response) var notoriskt frustrerande och begränsade till stela kommandon och menystrukturer. Moderna röstassistenter kan förstå naturliga talmönster, ta hänsyn till olika accenter och talstörningar och svara med alltmer naturligt klingande syntetiserade röster.
Sammanslagningen av dessa funktioner skapar verkligt multimodal konversations-AI som sömlöst kan växla mellan olika kommunikationslägen baserat på kontext och användarbehov. En användare kan börja med en textfråga om att reparera sin skrivare, skicka ett foto av felmeddelandet, få ett diagram som markerar relevanta knappar och sedan växla till röstinstruktioner medan deras händer är upptagna med reparationen.
Denna multimodala metod representerar inte bara ett tekniskt framsteg utan ett grundläggande skifte mot mer naturlig människa-datorinteraktion – att möta användare i vilket kommunikationsläge som helst som fungerar bäst för deras nuvarande kontext och behov.
Retrieval-Augmented Generation: Grundläggande AI i fakta
Trots sina imponerande förmågor har stora språkmodeller inneboende begränsningar. De kan "hallucinera" information och med säkerhet ange trovärdiga men felaktiga fakta. Deras kunskap är begränsad till vad som fanns i deras träningsdata, vilket skapar ett kunskapsgränsdatum. Och de saknar möjligheten att få tillgång till realtidsinformation eller specialiserade databaser om de inte är specifikt konstruerade för att göra det.
Retrieval-Augmented Generation (RAG) framträdde som en lösning på dessa utmaningar. Istället för att enbart förlita sig på parametrar som lärts in under träning kombinerar RAG-system språkmodellernas generativa förmågor med hämtningsmekanismer som kan få tillgång till externa kunskapskällor.
Den typiska RAG-arkitekturen fungerar så här:
Systemet tar emot en användarfråga
Det söker i relevanta kunskapsbaser efter information som är relevant för frågan
Det matar både frågan och den hämtade informationen till språkmodellen
Modellen genererar ett svar baserat på de hämtade fakta
Denna metod erbjuder flera fördelar:
Mer exakta, faktabaserade svar genom att genereringen baseras på verifierad information
Möjligheten att få tillgång till aktuell information utöver modellens träningsgräns
Specialiserad kunskap från domänspecifika källor som företagsdokumentation
Transparens och attribution genom att hänvisa till informationskällorna
För företag som implementerar konversationsbaserad AI har RAG visat sig vara särskilt värdefullt för kundtjänstapplikationer. En bankchatbot kan till exempel få tillgång till de senaste policydokumenten, kontoinformationen och transaktionsposterna för att ge exakta, personliga svar som skulle vara omöjliga med en fristående språkmodell.
Utvecklingen av RAG-system fortsätter med förbättringar i hämtningsnoggrannhet, mer sofistikerade metoder för att integrera hämtad information med genererad text och bättre mekanismer för att utvärdera tillförlitligheten hos olika informationskällor.
Retrieval-Augmented Generation (RAG) framträdde som en lösning på dessa utmaningar. Istället för att enbart förlita sig på parametrar som lärts in under träning kombinerar RAG-system språkmodellernas generativa förmågor med hämtningsmekanismer som kan få tillgång till externa kunskapskällor.
Den typiska RAG-arkitekturen fungerar så här:
Systemet tar emot en användarfråga
Det söker i relevanta kunskapsbaser efter information som är relevant för frågan
Det matar både frågan och den hämtade informationen till språkmodellen
Modellen genererar ett svar baserat på de hämtade fakta
Denna metod erbjuder flera fördelar:
Mer exakta, faktabaserade svar genom att genereringen baseras på verifierad information
Möjligheten att få tillgång till aktuell information utöver modellens träningsgräns
Specialiserad kunskap från domänspecifika källor som företagsdokumentation
Transparens och attribution genom att hänvisa till informationskällorna
För företag som implementerar konversationsbaserad AI har RAG visat sig vara särskilt värdefullt för kundtjänstapplikationer. En bankchatbot kan till exempel få tillgång till de senaste policydokumenten, kontoinformationen och transaktionsposterna för att ge exakta, personliga svar som skulle vara omöjliga med en fristående språkmodell.
Utvecklingen av RAG-system fortsätter med förbättringar i hämtningsnoggrannhet, mer sofistikerade metoder för att integrera hämtad information med genererad text och bättre mekanismer för att utvärdera tillförlitligheten hos olika informationskällor.
Samarbetsmodellen mellan människa och AI: Att hitta rätt balans
I takt med att konversationsbaserad AI-kapacitet har expanderat har relationen mellan människor och AI-system utvecklats. Tidiga chattrobotar positionerades tydligt som verktyg – begränsade i omfattning och uppenbarligen icke-mänskliga i sina interaktioner. Moderna system suddar ut dessa gränser och skapar nya frågor om hur man utformar effektivt samarbete mellan människa och AI.
De mest framgångsrika implementeringarna idag följer en samarbetsmodell där:
AI:n hanterar rutinmässiga, repetitiva frågor som inte kräver mänskligt omdöme
Människor fokuserar på komplexa fall som kräver empati, etiskt resonemang eller kreativ problemlösning
Systemet känner till sina begränsningar och eskalerar smidigt till mänskliga agenter när det är lämpligt
Övergången mellan AI och mänskligt stöd är sömlös för användaren
Mänskliga agenter har fullständig kontext av konversationshistoriken med AI:n
AI fortsätter att lära sig av mänskliga interventioner och utökar gradvis sina möjligheter
Denna metod inser att konversationsbaserad AI inte bör syfta till att helt ersätta mänsklig interaktion, utan snarare att komplettera den – hantera de stora, enkla frågor som förbrukar mänskliga agenters tid samtidigt som komplexa frågor når rätt mänsklig expertis.
Implementeringen av denna modell varierar mellan branscher. Inom sjukvården kan AI-chattrobotar hantera tidsbokning och grundläggande symptomscreening samtidigt som de säkerställer att medicinska råd kommer från kvalificerade yrkesverksamma. Inom juridiska tjänster kan AI hjälpa till med dokumentförberedelse och research, samtidigt som tolkning och strategier lämnas till advokater. Inom kundtjänst kan AI lösa vanliga problem samtidigt som komplexa problem skickas vidare till specialiserade agenter.
I takt med att AI-kapaciteten fortsätter att utvecklas kommer gränsen mellan vad som kräver mänskligt engagemang och vad som kan automatiseras att förskjutas, men den grundläggande principen kvarstår: effektiv konversations-AI bör förbättra mänskliga förmågor snarare än att bara ersätta dem.
De mest framgångsrika implementeringarna idag följer en samarbetsmodell där:
AI:n hanterar rutinmässiga, repetitiva frågor som inte kräver mänskligt omdöme
Människor fokuserar på komplexa fall som kräver empati, etiskt resonemang eller kreativ problemlösning
Systemet känner till sina begränsningar och eskalerar smidigt till mänskliga agenter när det är lämpligt
Övergången mellan AI och mänskligt stöd är sömlös för användaren
Mänskliga agenter har fullständig kontext av konversationshistoriken med AI:n
AI fortsätter att lära sig av mänskliga interventioner och utökar gradvis sina möjligheter
Denna metod inser att konversationsbaserad AI inte bör syfta till att helt ersätta mänsklig interaktion, utan snarare att komplettera den – hantera de stora, enkla frågor som förbrukar mänskliga agenters tid samtidigt som komplexa frågor når rätt mänsklig expertis.
Implementeringen av denna modell varierar mellan branscher. Inom sjukvården kan AI-chattrobotar hantera tidsbokning och grundläggande symptomscreening samtidigt som de säkerställer att medicinska råd kommer från kvalificerade yrkesverksamma. Inom juridiska tjänster kan AI hjälpa till med dokumentförberedelse och research, samtidigt som tolkning och strategier lämnas till advokater. Inom kundtjänst kan AI lösa vanliga problem samtidigt som komplexa problem skickas vidare till specialiserade agenter.
I takt med att AI-kapaciteten fortsätter att utvecklas kommer gränsen mellan vad som kräver mänskligt engagemang och vad som kan automatiseras att förskjutas, men den grundläggande principen kvarstår: effektiv konversations-AI bör förbättra mänskliga förmågor snarare än att bara ersätta dem.
Framtidens landskap: Vart konversationsbaserad AI är på väg
När vi blickar mot horisonten formar flera framväxande trender framtiden för konversations-AI. Denna utveckling lovar inte bara stegvisa förbättringar utan potentiellt transformativa förändringar i hur vi interagerar med teknik. Personalisering i stor skala: Framtida system kommer i allt högre grad att skräddarsy sina svar inte bara till det omedelbara sammanhanget utan också till varje användares kommunikationsstil, preferenser, kunskapsnivå och relationshistorik. Denna personalisering kommer att få interaktioner att kännas mer naturliga och relevanta, även om den väcker viktiga frågor om integritet och dataanvändning. Emotionell intelligens: Medan dagens system kan upptäcka grundläggande känslor, kommer framtida konversations-AI att utveckla mer sofistikerad emotionell intelligens – känna igen subtila känslomässiga tillstånd, reagera lämpligt på ångest eller frustration och anpassa sin ton och sitt tillvägagångssätt därefter. Denna förmåga kommer att vara särskilt värdefull inom kundtjänst, hälso- och sjukvård och utbildning. Proaktiv assistans: Istället för att vänta på explicita frågor kommer nästa generations konversationssystem att förutse behov baserat på sammanhang, användarhistorik och miljösignaler. Ett system kan märka att du schemalägger flera möten i en okänd stad och proaktivt erbjuda transportalternativ eller väderprognoser. Sömlös multimodal integration: Framtida system kommer att gå bortom att bara stödja olika modaliteter till att sömlöst integrera dem. En konversation kan flyta naturligt mellan text, röst, bilder och interaktiva element, och välja rätt modalitet för varje informationsbit utan att kräva explicit användarval.
Specialiserade domänexperter: Medan allmänt anställda assistenter kommer att fortsätta att förbättras, kommer vi också att se en ökning av högspecialiserad konversations-AI med djup expertis inom specifika domäner – juridiska assistenter som förstår rättspraxis och prejudikat, medicinska system med omfattande kunskap om läkemedelsinteraktioner och behandlingsprotokoll, eller finansiella rådgivare som är bekanta med skattelagar och investeringsstrategier.
Verkligt kontinuerligt lärande: Framtida system kommer att gå bortom regelbunden omskolning till kontinuerligt lärande från interaktioner och bli mer hjälpsamma och personliga över tid samtidigt som de bibehåller lämpliga integritetsskydd.
Trots dessa spännande möjligheter kvarstår utmaningar. Integritetsproblem, minskning av partiskhet, lämplig transparens och att etablera rätt nivå av mänsklig tillsyn är ständiga frågor som kommer att forma både tekniken och dess reglering. De mest framgångsrika implementeringarna kommer att vara de som tar itu med dessa utmaningar på ett genomtänkt sätt samtidigt som de levererar ett genuint värde till användarna.
Det som är tydligt är att konversations-AI har gått från en nischteknik till ett vanligt gränssnittsparadigm som i allt högre grad kommer att mediera våra interaktioner med digitala system. Den evolutionära vägen från ELIZAs enkla mönstermatchning till dagens sofistikerade språkmodeller representerar ett av de viktigaste framstegen inom människa-datorinteraktion – och resan är långt ifrån över.
Specialiserade domänexperter: Medan allmänt anställda assistenter kommer att fortsätta att förbättras, kommer vi också att se en ökning av högspecialiserad konversations-AI med djup expertis inom specifika domäner – juridiska assistenter som förstår rättspraxis och prejudikat, medicinska system med omfattande kunskap om läkemedelsinteraktioner och behandlingsprotokoll, eller finansiella rådgivare som är bekanta med skattelagar och investeringsstrategier.
Verkligt kontinuerligt lärande: Framtida system kommer att gå bortom regelbunden omskolning till kontinuerligt lärande från interaktioner och bli mer hjälpsamma och personliga över tid samtidigt som de bibehåller lämpliga integritetsskydd.
Trots dessa spännande möjligheter kvarstår utmaningar. Integritetsproblem, minskning av partiskhet, lämplig transparens och att etablera rätt nivå av mänsklig tillsyn är ständiga frågor som kommer att forma både tekniken och dess reglering. De mest framgångsrika implementeringarna kommer att vara de som tar itu med dessa utmaningar på ett genomtänkt sätt samtidigt som de levererar ett genuint värde till användarna.
Det som är tydligt är att konversations-AI har gått från en nischteknik till ett vanligt gränssnittsparadigm som i allt högre grad kommer att mediera våra interaktioner med digitala system. Den evolutionära vägen från ELIZAs enkla mönstermatchning till dagens sofistikerade språkmodeller representerar ett av de viktigaste framstegen inom människa-datorinteraktion – och resan är långt ifrån över.





